新しい理論を導入する際、架空のデータを用意できると色々と便利です。ただ自分で1から書こうとすると面倒なのも事実。なので本ページのコードをコピーすればある程度使えるような形に整理してみました。
基本のコード
■ 同じものを繰り返す
rep(c(1,2,3), times=2) # ベクトル
rep(c("fair","good"), times=c(2,3)) # 文字列
rep(paste("pat", c(1:3), sep="_"), times=2) # paste関数
■ 値を元にカテゴリデータを生成する
x = c(90, 55, 79, 80, 100)
cut(x,breaks=c(0,80,100), labels=c("不合格","合格"), right = FALSE, include.lowest = TRUE)
# 意味:0-80未満なら不合格,80以上-100以内なら合格と表示される
# 引数:right = False 境界80を左に含めない , include.lowest = TRUE 終端100を含む
■ 等差数列
seq(1, 5, by=2) # 1,3,5
■ 乱数生成
rnorm(生成する乱数の数, 平均値, 標準偏差) # 正規分布
runif(20, min = 1, max = 100) # 一様分布,小数も含む
as.integer(runif(20, min = 1, max = 100)) # 一様分布,整数のみ
rpois(n=100, lambda=5) #ポアソン分布
rbinom(n=100, size = 50, prob = 0.5) # 二項分布,成功確率50%を50回試行した結果の値を100個生成特殊パターンを生成するコード
曲線
set.seed(123)
data = data.frame()
# --------------------------------------------------
# Xが大きくなるにつれてYの傾きが大きくなるデータを生成
# --------------------------------------------------
for (i in 1:100) {
slope = 5 * i # Yの傾きをXに比例して増加させる
y = slope * i + rnorm(1, mean = 0, sd = 500) # 線形回帰にノイズを加える
data = rbind(data, data.frame(x = i, y = y))
}
# --------------------------------------------------
# 線形回帰で予測・可視化
# --------------------------------------------------
model = lm(y ~ x ,data = data)
tmp = data.frame(pred = predict(model),resu = data$y,x = data$x)
ggplot(data = tmp) +
geom_point(mapping = aes(x=x,y=pred,color = '予測値')) +
geom_point(mapping = aes(x=x,y=resu,color = '実測値')) +
theme_classic()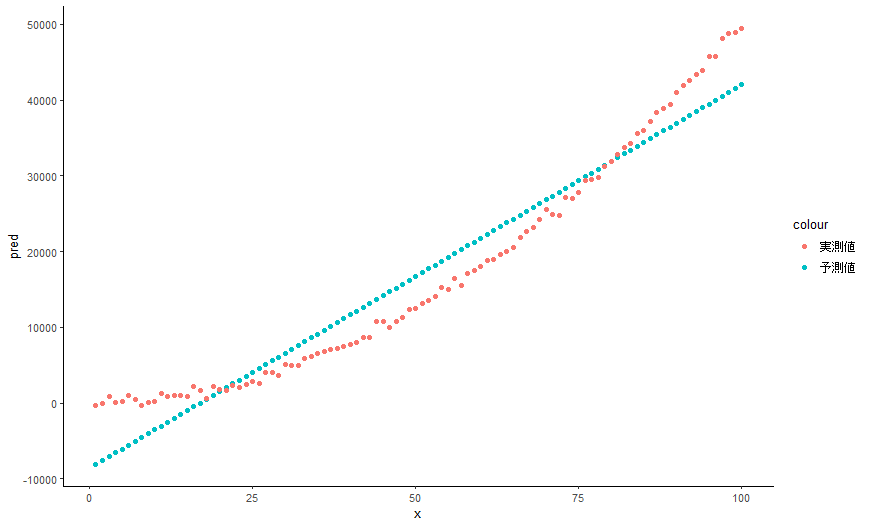
相関を持つ2変数
set.seed(123)
data = data.frame()
# 相関を生成する関数を用意
CorRand = function(n, mu, sd, r){ # r:相関係数
x = rnorm(n=n, mean=mu, sd=sd)
e1 = rnorm(n=n, mean=mu, sd=sd)
e2 = rnorm(n=n, mean=mu, sd=sd)
return(cbind(sqrt(r)*x+sqrt(1-r)*e1, sqrt(r)*x+sqrt(1-r)*e2))}
# 生成・格納
mt = CorRand(1000, 0, 1, 0.8)
x = mt[,1]
y = 1 + 2 * mt[,2]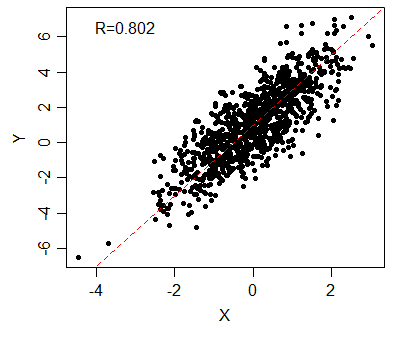
回帰モデルに基づいたデータの作成
n = 1000
b0 = 10
b1 = 10
x1 = rnorm(n=n)
e = rnorm(n=n, sd=10)
y = b0 + b1*x1 + e
plot(x,y)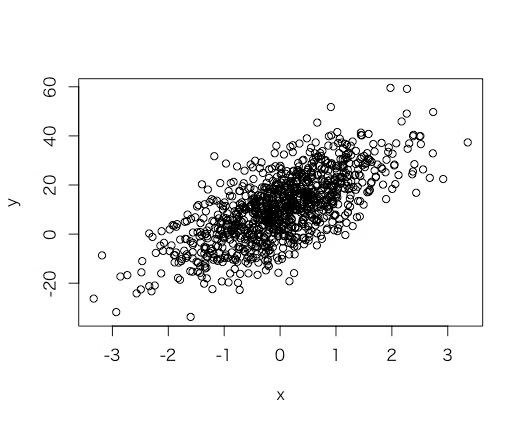
時系列データ
base_val = c(rep(0,150),rep(3,150)) # 何らかの変化があったイメージ
seasonal_val = rep(c(15,13,11,rep(0,47)),6) # 15,13,11,0,0,…,15,13,11,0,0,…
trend_val = seq(0,8,length=300) # 0 ~ 8 まで300分割の等差数列
error = rnorm(300) # ホワイトノイズ
x = base_val+trend_val+seasonal_val+error
xt = ts(data = x,frequency=50) # frequency:time(回数)が変わる
plot(xt)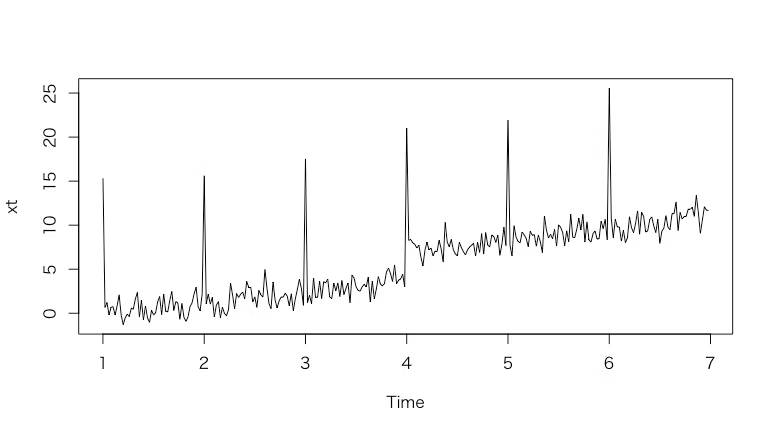
(コードは一部改編しています)
多重共線性
x1 = rnorm(100, 10, 1)
x2 = rnorm(100, 10, 2)
x3 = x1 * 2 + rnorm(100, 10, 0.01)
y = x1 + 2 * x2 + 3 * x3 + rnorm(100, 0, 1)
data = data.frame(y,x1,x2,x3)
pairs(data) # 散布図行列を確認する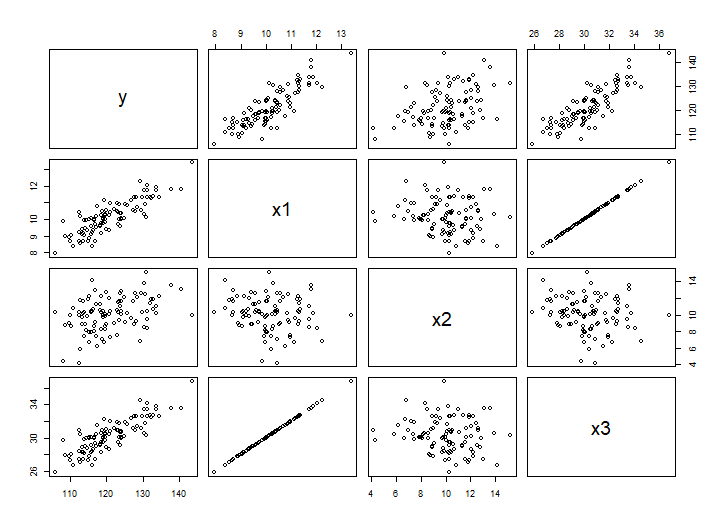
その他の参考リンク
R言語 標準データセットの私的まとめ https://qiita.com/wakuteka/items/95ac758070f6f4d89a96
R言語のcut関数の使い方 https://blog.data-hacker.net/2013/05/rcut.html
Rで統計解析 ~ 重回帰分析 ~ https://cvtech.cc/r-lmm/

コメント