時系列データの分解方法を調べる機会があったのですが、調べた限りではSTLまたはdecompose(古典的分解と呼ばれることも)が使われることが多いようでした。それぞれの主要なコードおよび動作の違いに関してまとめました。
なお、通常はグラフ化などして確認したほうがイメージ沸きやすいですが、先人の方がたくさん既に作っているので気になる方は補足欄をご覧ください。
STL:Seasonal and Trend decomposition using Loess
R
library(forecast)
stl_obj = stl(ts, s.window,t.window = NULL,robust = FALSE) # 分解
stl_obj$time.series[,1] # seasonal
stl_obj$time.series[,2] # trend
stl_obj$time.series[,3] # remainder
plot(stl_obj) # 可視化python1
import statsmodels.api as sm
from statsmodels.tsa.seasonal import STL
stl_obj = STL(ts, period=13, robust=True).fit() # 分解
stl_obj.trend # trend
stl_obj.seasonal # seasonal
stl_obj.resid # resid
stl_obj .plot() # 可視化
plt.show()【R】s.window【py】period:
seasonality window。文字列 “periodic ” で自動設定 または 整数値で手動設定(Clevelandの主張によると7以上の奇数である必要がある2)
【R】t.window【py】trend:
trend window。こちらも奇数である必要がある3。トレンド・循環成分と季節成分がどれだけ速く変化できるかを調整する。窓を小さくすると、より速く変化できる。
【R】robust【py】robust:
外れ値に対して強い「ロバストフィッティング」を適用するかどうか。
decompose
R4
dec_obj = decompose(ts ,type = c("additive" or "multiplicative")) # 分解 ,加法or乗法モデルの選択
dec_obj$seasonal
dec_obj$trend
dec_obj$random
# seasadj(dec_obj) を使うことで季節調整済みデータ(trend + 残差)を抽出できる
# seasadj(stl_obj) でも可Python5
import statsmodels.api as sm
from statsmodels.tsa.seasonal import STL
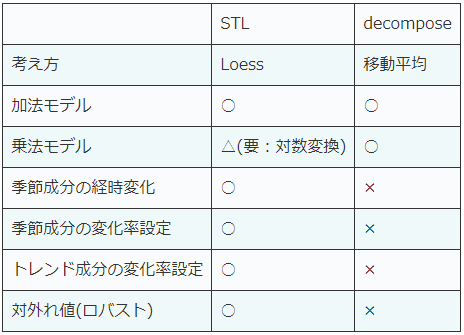
cycle, trend = sm.tsa.filters.hpfilter(ts, 144)STLとdecomposeの比較
| STL | decompose | |
| 考え方 | Loess | 移動平均 |
| 加法モデル | ○ | ○ |
| 乗法モデル | △(要:対数変換) | ○ |
| 季節成分の経時変化 | ○ | × |
| 季節成分の変化率設定 | ○ | × |
| トレンド成分の変化率設定 | ○ | × |
| 対外れ値(ロバスト) | ○ | × |
結論
decomposeをわざわざ使うメリットは薄いので、基本的にはSTLを使うと考えて良さそう。
補足
- セールスアナリティクス「(Python編) 時系列データをサクッとSTLでトレンド・季節性に分解」
https://www.salesanalytics.co.jp/datascience/datascience003/ ↩︎ - 調べてもよく分からなかった。 ↩︎
- オーストラリアモナシュ大学「予測: 原理と実践」3.6 STL分解 https://otexts.com/fppjp/stl.html#fig:empl-stl2 ↩︎
- RDocumentation「decompose: Classical Seasonal Decomposition by Moving Averages」
https://www.rdocumentation.org/packages/stats/versions/3.6.2/topics/decompose ↩︎ - QIITA「【要素分解入門】時系列解析の手法をRとpythonで並べてみる」
https://qiita.com/MuAuan/items/3a0273ba8be4035895be ↩︎
コメント